The Best LLM for Cyber Threat Intelligence: OpenAI, Anthropic, Groq

Nikoloz Kokhreidze
We compare AI services and LLMs for cyber threat intelligence to find the best one for speed, context and cost.

Imagine a project that uses AI language models to make threat information easier to understand. The goal is simple:
1. Create a structured way to store threat data (using JSON)
2. Feed in a threat report
3. Have the AI analyze the report and fill in the structured data
4. Use the structured data for further analysis
To make this work, we'll use Python and FastAPI to manage the process, and connect to AI services from companies like OpenAI, Anthropic, and Groq. Since analyzing threat reports can take some time, we'll use asynchronous functions (async) to keep things running smoothly.
We want to make sure the AI gives us quick and accurate results, so we'll be testing several different AI language models:
- Two models from Anthropic (claude-3-opus-20240229 and claude-3-sonnet-20240229)
- Two models from OpenAI (gpt-4-0125-preview and gpt-3.5-turbo-0125)
- Two models running on Groq hardware (llama2-70b-4096 by Meta and mixtral-8x7b-32768 by Mixtral)
We'll look at how fast each model is, how much it costs to use, and how well it understands the threat reports. The best model for this project will balance speed, price, and accuracy.
Preparing the JSON Structure and Functions
To identify the best AI service for our cybersecurity use case, we create a 43-line JSON structure containing threat information (attack type, TTPs, vulnerabilities, CVE IDs, etc.) and Mandos Brief structure, with examples and details to assist the language model. By combining JSON structure with a simple prompt to fill it out, we get a 1852-character, 191-word system message that sets clear expectations for the language model's output.
Next, we provide content for the LLM to analyze and populate the JSON. We choose a joint cybersecurity advisory about APT28 from the FBI containing all the necessary items requested in the JSON. We copy the PDF body and save it as a file (.md or .txt), resulting in a 17499-character, 2234-word text.
With the content prepared, our next step is to create functions, starting with grab_content(). This async function is designed to consume a URL or file containing text and return the content, which we will use for both the system message and prompt.
# Fetch content from a given URL or local file path.
async def grab_content(path_or_url):
try:
# Check if the input is a URL or a local file path
if path_or_url.startswith('http://') or path_or_url.startswith('https://'):
# The input is a URL, fetch the content from the web
response = requests.get(path_or_url)
response.raise_for_status() # Raises an exception for HTTP errors
content = response.text
else:
# The input is assumed to be a local file path, read the file content
with open(path_or_url, 'r', encoding='utf-8') as file:
content = file.read()
return content
except requests.RequestException as e:
return str(e)
except FileNotFoundError as e:
return f"File not found: {e}"
except Exception as e:
return f"An error occurred: {e}"Next, we need to create functions for each AI service. To do this, we configure parameters such as temperature, top_p, frequency_penalty, presence_penalty, and max_tokens. For this evaluation, we will set the same temperature and parameters for all AI services to avoid hallucinations as much as possible.
The example provided shows how to call the OpenAI API.
# Asynchronously calls the OpenAI API with the specified messages and model.
async def call_openai_api_async(messages, model="gpt-4-0125-preview"):
try:
response = await async_openai_client.chat.completions.create(
model=model,
messages=messages,
temperature=0.0,
top_p=1,
frequency_penalty=0.1,
presence_penalty=0.1,
max_tokens=2048
)
incident_report = response.choices[0].message.content
# Access usage information using dot notation.
usage_info = response.usage
# Calculate the cost based on the usage.
model_used = response.model
print(usage_info)
# Assuming ai_api_calculate_cost returns a dictionary with cost details
cost_data = ai_api_calculate_cost(usage_info, model=model_used)
# Combine incident_report and cost_data
combined_response = {
"incidentReport": incident_report,
"costData": cost_data
}
return combined_response
except Exception as e:
return f"An error occurred: {e}"Let's break down how this function works. We supply the call_openai_api_async() function with the necessary messages and model parameters. This function sends an asynchronous request to the OpenAI API.
Once the API processes our request, it sends back a response. The call_openai_api_async() function parses this response and extracts two key pieces of information:
1. The filled-out JSON data
2. Usage information, which includes the number of tokens used for both the prompt and the response
The usage data is then passed to the ai_api_calculate_cost() function. This function takes the token usage information and calculates the cost in US dollars based on the pricing information provided by the AI service providers at the time of publishing (let me know in the comments if you want to see this function as well).
The cost calculation is based on pricing information available at the date of publishing of this post and shared by AI service providers:
- OpenAI Pricing - http://openai.com/pricing
- Anthropic Pricing - https://www.anthropic.com/api
- Groq Pricing - https://wow.groq.com
Let's configure a function to trigger the process. While we could directly provide messages and config to call_openai_api_async(), we'll create a separate function as it will eventually serve as an API endpoint. This approach also allows our project to handle more extensive use cases than demonstrated in this example.
@app.post("/main/")
async def main(url: UrlBase):
try:
# Read system message (system prompt + JSON)
system_content = await grab_content(system_message.md)
# Read the article content
article = await grab_content("test_article.md")
# Messages for OAI and GROQ
# NOTE: You will have to adapt this to Anthropic API since it only recognizes "user" and "assistant" messages
messages = [
{"role": "system", "content": system_content},
{"role": "user", "content": article}
]
combined_response = await call_openai_api_async(messages)
return (combined_response)
except Exception as e:
print(e)
raise HTTPException(status_code=500, detail="There was an error on our side. Try again later.")Now that we have messages and calculation information, it's time to start evaluations.
Evaluation Methodology
Let's break down the evaluation criteria for the AI services:
- Speed - We measure the time it takes from providing the article content to receiving the final results from the AI service. We won't stream the AI's response but will wait for the full response. We'll use Postman, the API testing tool, to get the time information.
- Content Awareness - We assess how well the LLM recognizes the content and contextualizes it by filling out the JSON. I will manually review this.
- Total Cost - We calculate how much we have to pay the AI service for outputting filled out JSON. The cost will be represented as a sum of the prompt and response costs.
Each test starts when we initiate the main() function and ends when we receive the response. We supply each LLM with the same prompt and article text. We then manually review the filled-out JSON and identify any shortcomings.
Limitations and Caveats
Here are some important caveats and limitations to keep in mind as we evaluate the performance of these large language models (LLMs):
- Our evaluation is subjective since it's based on our custom prompt, instructions, and supplied content. If we use different prompts or content, we may get different results.
- The performance of the LLMs may vary depending on the complexity, length, or domain of the input text we provide. Let me know in the comments if you want us to evaluate other cybersecurity-related topics to further test their capabilities.
- Latency from my location to the closest server will vary for each provider, which can impact the perceived speed and responsiveness of the LLMs.
- Groq is utilizing custom chips that make LLM processing much faster, which may give them an advantage in terms of processing speed compared to other providers.
AI Language Model Performance: Detailed Results
We start sending the same article content to each LLM and AI service and analyze the results. Here is how it goes down.
Evaluating Anthropic's Claude 3 Opus LLM for Cyber Threat Intelligence Effectiveness
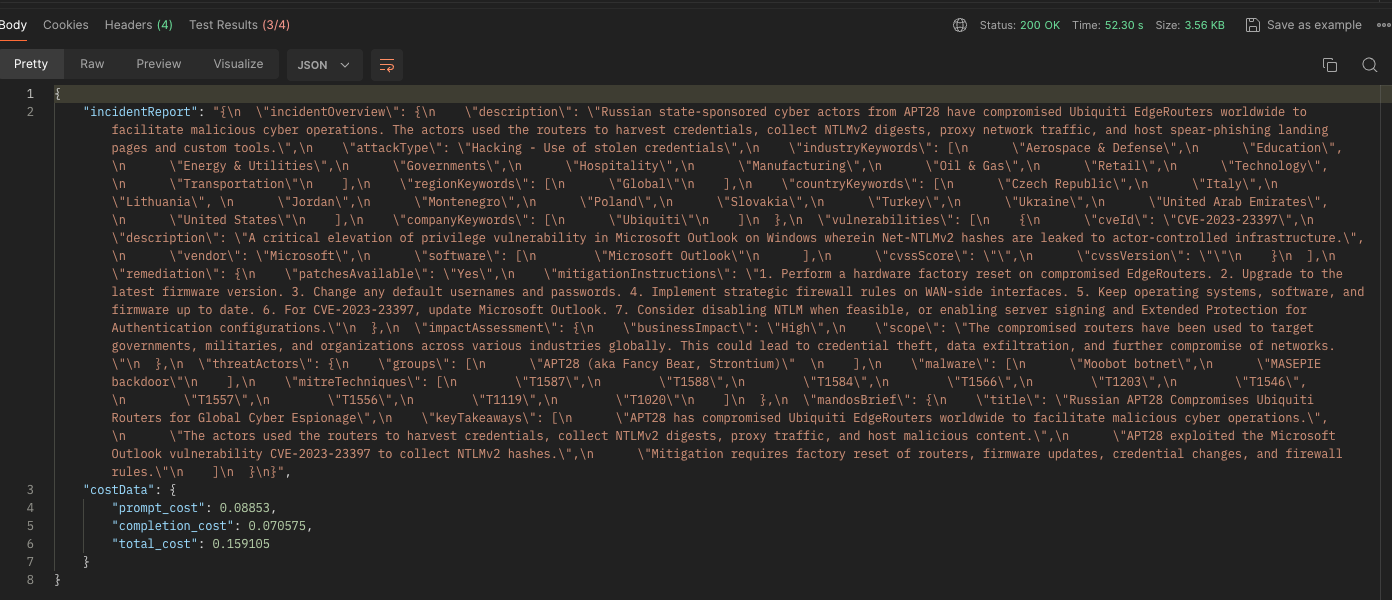
Model: claude-3-opus-20240229
Speed (seconds): 52.30s
Prompt Cost: $0.08853
Completion Cost: $0.070575
Total Cost: $0.159105
Content Awareness:
- Opus LLM identifies the affected regions as
global, which matches the report since countries from various regions were impacted. - The list of affected countries provided by Opus only includes those specifically mentioned as targeted by the threat actor. Our original prompt was more open-ended, asking for a general "List of countries", so we gave LLM some freedom to decide. The report does note additional countries were involved in the response: "The FBI, NSA, US Cyber Command, and international partners – including authorities from Belgium, Brazil, France, Germany, Latvia, Lithuania, Norway, Poland, South Korea, and the United Kingdom."
- For the company keyword, Opus mentions Ubiquiti, while the report also discusses Microsoft.
- CVSS scores are not included in the report and Opus appropriately leaves that value blank.
- Opus successfully identifies all 7 mitigation instructions provided in the report.
- 1. Perform a hardware factory reset on compromised EdgeRouters.
- 2. Upgrade to the latest firmware version.
- 3. Change any default usernames and passwords.
- 4. Implement strategic firewall rules on WAN-side interfaces.
- 5. Keep operating systems, software, and firmware up to date.
- 6. For CVE-2023-23397, update Microsoft Outlook.
- 7. Consider disabling NTLM when feasible, or enabling server signing and Extended Protection for Authentication configurations.
- Opus assesses business impact as
High. - In terms of threat actor groups, Opus correctly identifies them as
APT28 (aka Fancy Bear, Strontium),which the report equates to the Russian General Staff Main Intelligence Directorate (GRU), 85th Main Special Service Center (GTsSS). - Anthropic's new LLM correctly identifies the two malware strains
"malware": [
"Moobot botnet",
"MASEPIE backdoor"
]- Opus accurately identifies all 10 ATT&CK Techniques discussed in the report..
- The model provides an effective summary of the key points.
"title": "Russian APT28 Compromises Ubiquiti Routers for Global Cyber Espionage",
"keyTakeaways": [
"APT28 has compromised Ubiquiti EdgeRouters worldwide to facilitate malicious cyber operations.",
"The actors used the routers to harvest credentials, collect NTLMv2 digests, proxy traffic, and host malicious content.",
"APT28 exploited the Microsoft Outlook vulnerability CVE-2023-23397 to collect NTLMv2 hashes.",
"Mitigation requires factory reset of routers, firmware updates, credential changes, and firewall rules."
]Evaluating Anthropic's Claude 3 Sonnet LLM for Cyber Threat Intelligence Effectiveness
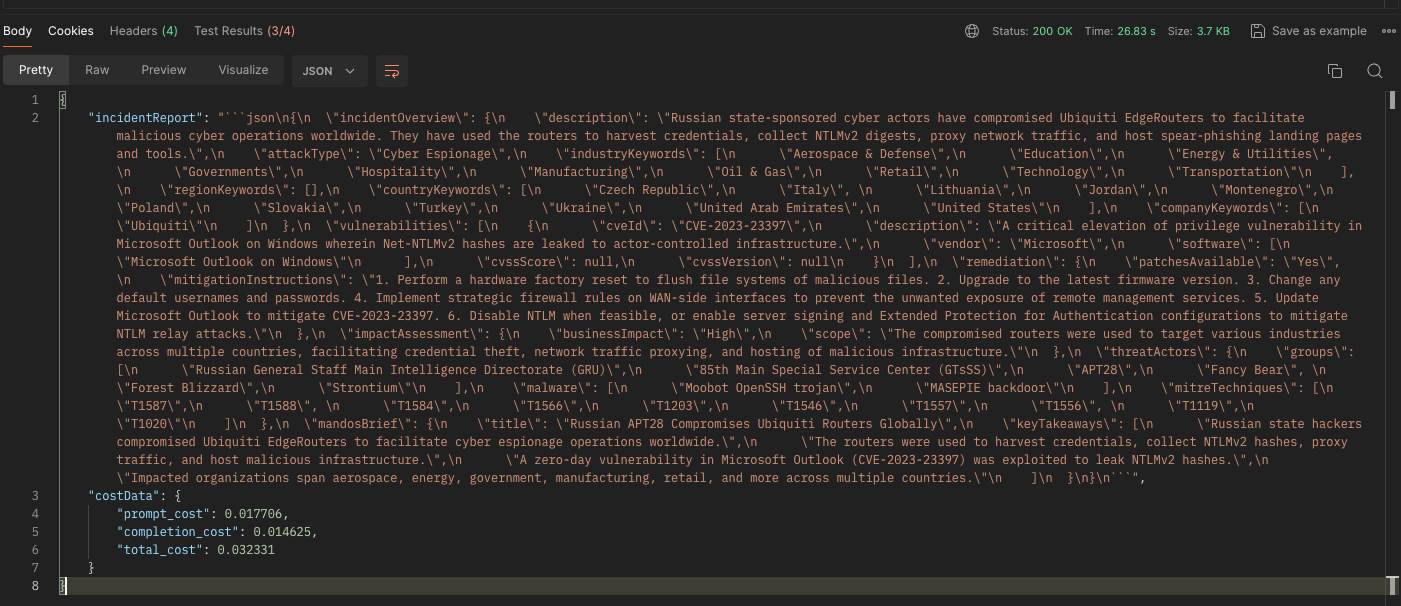
Model: claude-3-sonnet-20240229
Speed (seconds): 26.83
Prompt Cost: $0.017706
Completion Cost: $0.014625
Total Cost: $0.032331
Content Awareness:
- We see that Sonnet LLM left the region blank.
- Sonnet provides the list of affected countries mentioned in the report, but not all countries.
- Like Opus, Sonnet only identifies 1 company - Ubiquiti.
- The report does not mention any CVSS scores, so Sonnet set that value to
null. - Sonnet finds 6 mitigation instructions that were all in the provided report. However, it missed detecting the additional recommendation to "Keep operating systems, software, and firmware up to date." I suspect this was due to setting the
temperatureto0.0, which is consistent across all LLMs we are testing in this post. Here are the mitigations from Sonnet:- 1. Perform a hardware factory reset to flush file systems of malicious files.
- 2. Upgrade to the latest firmware version.
- 3. Change any default usernames and passwords.
- 4. Implement strategic firewall rules on WAN-side interfaces to prevent the unwanted exposure of remote management services.
- 5. Update Microsoft Outlook to mitigate CVE-2023-23397.
- 6. Disable NTLM when feasible, or enable server signing and Extended Protection for Authentication configurations to mitigate NTLM relay attacks.
- Sonnet assesses business impact as
High. - It identified multiple threat actor groups like
"Russian General Staff Main Intelligence Directorate (GRU)", "85th Main Special Service Center (GTsSS)", "APT28", "Fancy Bear", "Forest Blizzard", "Strontium". While the report mentioned all these groups, they actually refer to the same entity, as stated in this excerpt: "...the Russian General Staff Main Intelligence Directorate (GRU), 85th Main Special Service Center (GTsSS), also known as APT28, Fancy Bear, and Forest Blizzard (Strontium), have used compromised..." - The model correctly identifies two malware strains:
"malware": [
"Moobot OpenSSH trojan",
"MASEPIE backdoor"
],- Sonnet also correctly captured all 10 ATT&CK Techniques mentioned.
- Here is the summary from Sonnet:
"title": "Russian APT28 Compromises Ubiquiti Routers Globally",
"keyTakeaways": [
"Russian state hackers compromised Ubiquiti EdgeRouters to facilitate cyber espionage operations worldwide.",
"The routers were used to harvest credentials, collect NTLMv2 hashes, proxy traffic, and host malicious infrastructure.",
"A zero-day vulnerability in Microsoft Outlook (CVE-2023-23397) was exploited to leak NTLMv2 hashes.",
"Impacted organizations span aerospace, energy, government, manufacturing, retail, and more across multiple countries."
]Evaluating OpenAI's GPT-4 LLM for Cyber Threat Intelligence Effectiveness
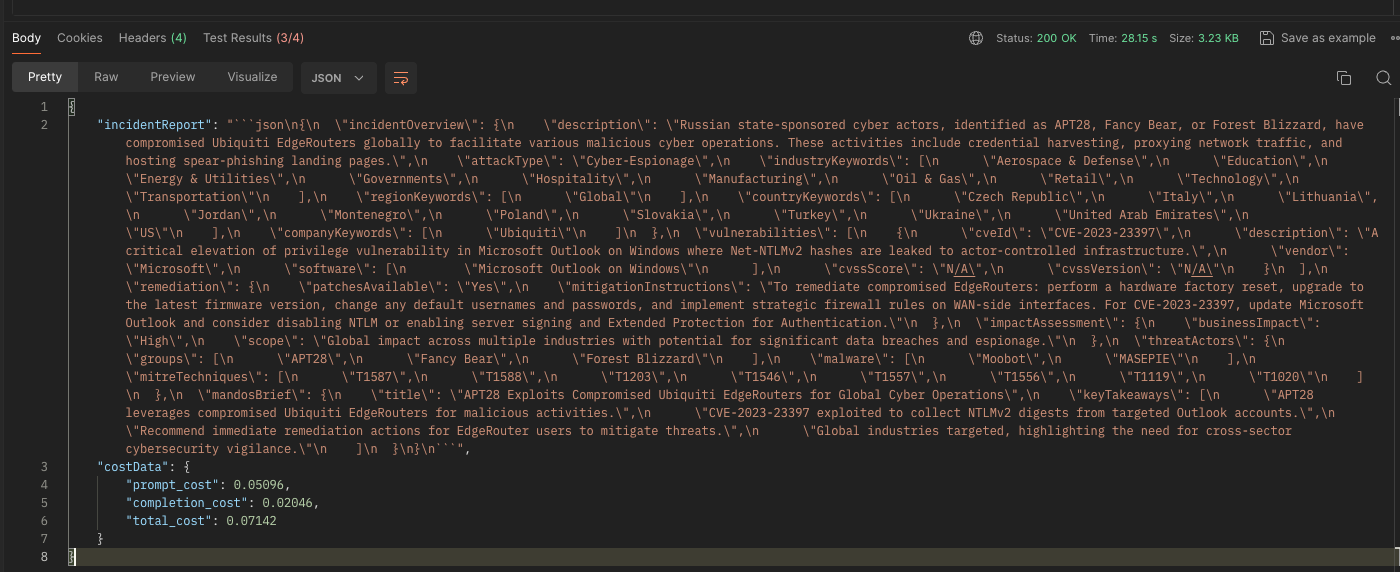
Model: gpt-4-0125-preview
Speed (seconds): 28.15
Prompt Cost: $0.05096
Completion Cost: $0.02046
Total Cost: $0.07142
Content Awareness:
- GPT-4 LLM recognizes the affected regions as global, just like Opus did.
- Consistent with the previous two models, GPT-4 also lists only the impacted countries.
- In the report, OpenAI's GPT-4 discovered a single company: Ubiquiti.
- As the report did not mention CVSS scores, the model set the value to
N/A. - GPT-4 organizes the mitigation instructions in a different way. It omits the instruction "Keep operating systems, software, and firmware up to date." which was present in the report and identified by Opus.
"mitigationInstructions": "To remediate compromised EdgeRouters: perform a hardware factory reset, upgrade to the latest firmware version, change any default usernames and passwords, and implement strategic firewall rules on WAN-side interfaces. For CVE-2023-23397, update Microsoft Outlook and consider disabling NTLM or enabling server signing and Extended Protection for Authentication."
},- The model assessed business impact as
High. - Similar to Sonnet, GPT-4 identifies multiple threat actor groups
"APT28", "Fancy Bear", "Forest Blizzard". These groups are more closely related to actual cyber threat actors compared to the ones from Sonnet (GRU). However, as mentioned earlier, these groups are associated with the same actor. - Interestingly, GPT-4 identifies only 8 ATT&CK Techniques, while the report states 10.
- When it comes to summarizing the content, GPT-4 provides us with the following:
"title": "APT28 Exploits Compromised Ubiquiti EdgeRouters for Global Cyber Operations",
"keyTakeaways": [
"APT28 leverages compromised Ubiquiti EdgeRouters for malicious activities.",
"CVE-2023-23397 exploited to collect NTLMv2 digests from targeted Outlook accounts.",
"Recommend immediate remediation actions for EdgeRouter users to mitigate threats.",
"Global industries targeted, highlighting the need for cross-sector cybersecurity vigilance."
]Evaluating OpenAI's GPT-3.5 LLM for Cyber Threat Intelligence Effectiveness
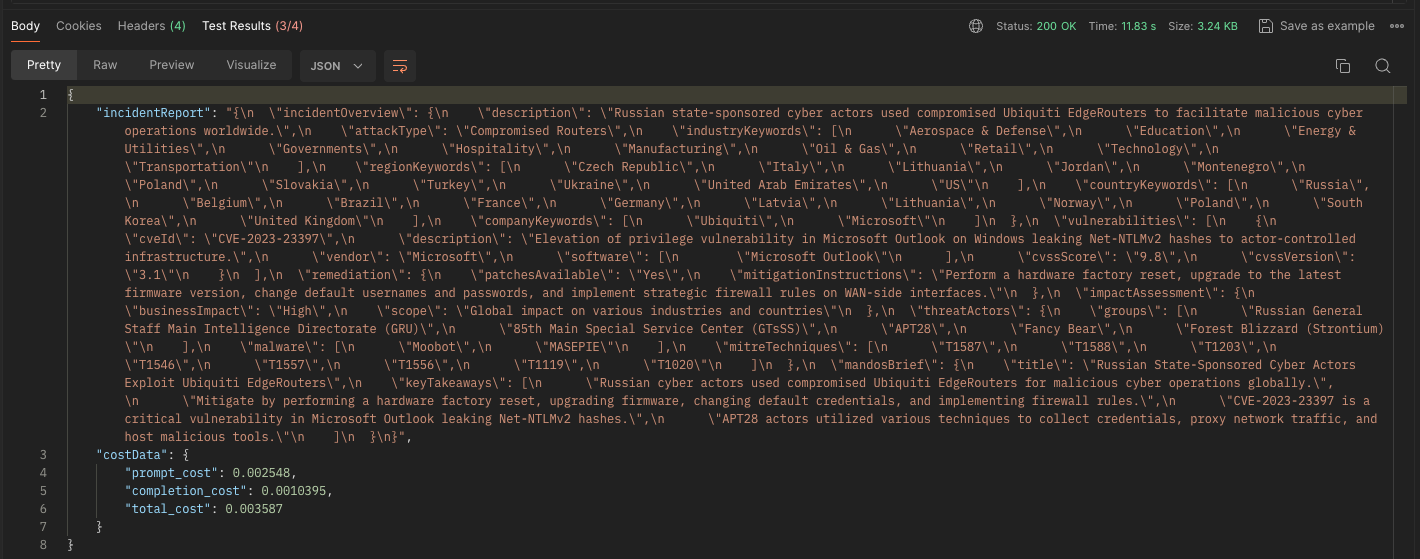
Model: gpt-3.5-turbo-0125
Speed (seconds): 11.83
Prompt Cost: $0.002548
Completion Cost: $0.0010395
Total Cost: $0.003587
Content Awareness:
- Interestingly GPT-3.5 language models puts the list of affected countries in JSON object for regions.
- Within the countries object, it enumerates the nations that contributed to this report.
- GPT-3.5 detected two companies from the report
UbiquitiandMicrosoft. - Fascinatingly, GPT-3.5 accurately determined the CVSS score of
9.8and the CVSS version 3.1, despite these details being absent from the report. We might argue that this specific CVE-2023-23397 was included in the training data, but there's a problem with this assertion. Based on OpenAI's model information, the gpt-3.5-turbo-0125 model's training data extends only until September 2021. However, the CVE was added to NIST's Vulnerability Database on March 14, 2023. To confirm that the language model wasn't hallucinating, I conducted the test two more times, and in both instances, it supplied the correct information. Strange that GPT-4.5 did not provide CVSS scoring information as its training data extends much further, until up to Dec 2023. - Compared to other models evaluated above, the mitigation instructions provided by the model were incomplete. As we can observe, updating Microsoft Outlook and disabling NTLM are not mentioned.
"mitigationInstructions": "Perform a hardware factory reset, upgrade to the latest firmware version, change default usernames and passwords, and implement strategic firewall rules on WAN-side interfaces."- GPT-3.5 assesses business impact as
High. - This model identifies multiple threat actors
"Russian General Staff Main Intelligence Directorate (GRU)", "85th Main Special Service Center (GTsSS)", "APT28", "Fancy Bear", "Forest Blizzard (Strontium)". All of them are alternative names for the same group as indicated in the report. - Similar to its smarter sibling, GPT-3.5 identifies only 8 ATT&CK Techniques out of 10.
- In terms of summarizing the content, GPT-3.5 provides the following:
"title": "Russian State-Sponsored Cyber Actors Exploit Ubiquiti EdgeRouters",
"keyTakeaways": [
"Russian cyber actors used compromised Ubiquiti EdgeRouters for malicious cyber operations globally.",
"Mitigate by performing a hardware factory reset, upgrading firmware, changing default credentials, and implementing firewall rules.",
"CVE-2023-23397 is a critical vulnerability in Microsoft Outlook leaking Net-NTLMv2 hashes.",
"APT28 actors utilized various techniques to collect credentials, proxy network traffic, and host malicious tools."
]
}Evaluating LLAMA LLM on Groq for Cyber Threat Intelligence Effectiveness
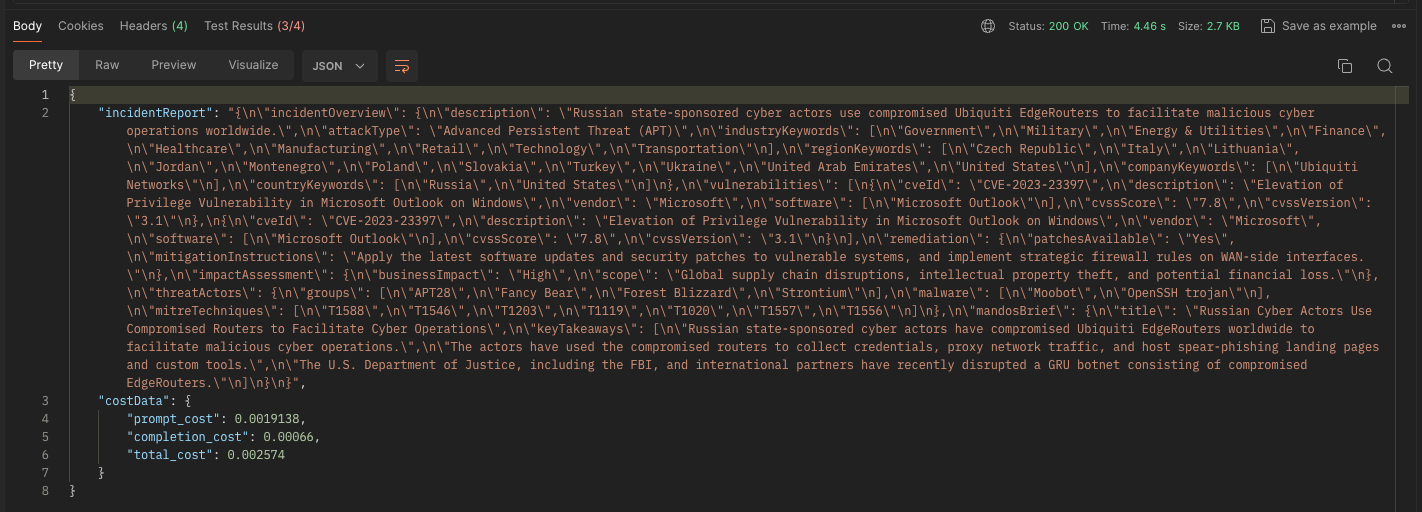
Model: llama2-70b-4096
Speed (seconds): 4.46
Prompt Cost: $0.0019138
Completion Cost: $0.00066
Total Cost: $0.002574
Content Awareness:
- LLAMA places the list of affected countries in a JSON object for regions.
- However, in the countries object, it only lists 2 out of the 11 countries that participated in the report.
- When it comes to extracting companies from the report, this model manages to identify just 1 out of 2: Ubiquiti Networks.
- Regarding vulnerabilities, Meta's LLM behaves oddly. It provides two entries for the same vulnerability, CVE-2023-23397. These vulnerability entries are accompanied by seemingly hallucinated CVSS Score,
7.8. - The mitigation instructions provided by LLAMA are quite limited, with only 2 out of 7 being included in the output.
"mitigationInstructions": "Apply the latest software updates and security patches to vulnerable systems, and implement strategic firewall rules on WAN-side interfaces."- Just as previous models LLAMA assesses business impact as
High. - The LLAMA finds multiple threat actors
"APT28", "Fancy Bear", "Forest Blizzard", "Strontium". - In terms of ATT&CK Techniques, this model manages to detect only 7 out of 10. Which is poorest score so far.
- LLAMA also provides a limited summary with 3 takeaways instead of the usual 4.
"title": "Russian Cyber Actors Use Compromised Routers to Facilitate Cyber Operations",
"keyTakeaways": [
"Russian state-sponsored cyber actors have compromised Ubiquiti EdgeRouters worldwide to facilitate malicious cyber operations.",
"The actors have used the compromised routers to collect credentials, proxy network traffic, and host spear-phishing landing pages and custom tools.",
"The U.S. Department of Justice, including the FBI, and international partners have recently disrupted a GRU botnet consisting of compromised EdgeRouters."
]
}Evaluating Mixtral 8x7b LLM on Groq for Cyber Threat Intelligence Effectiveness
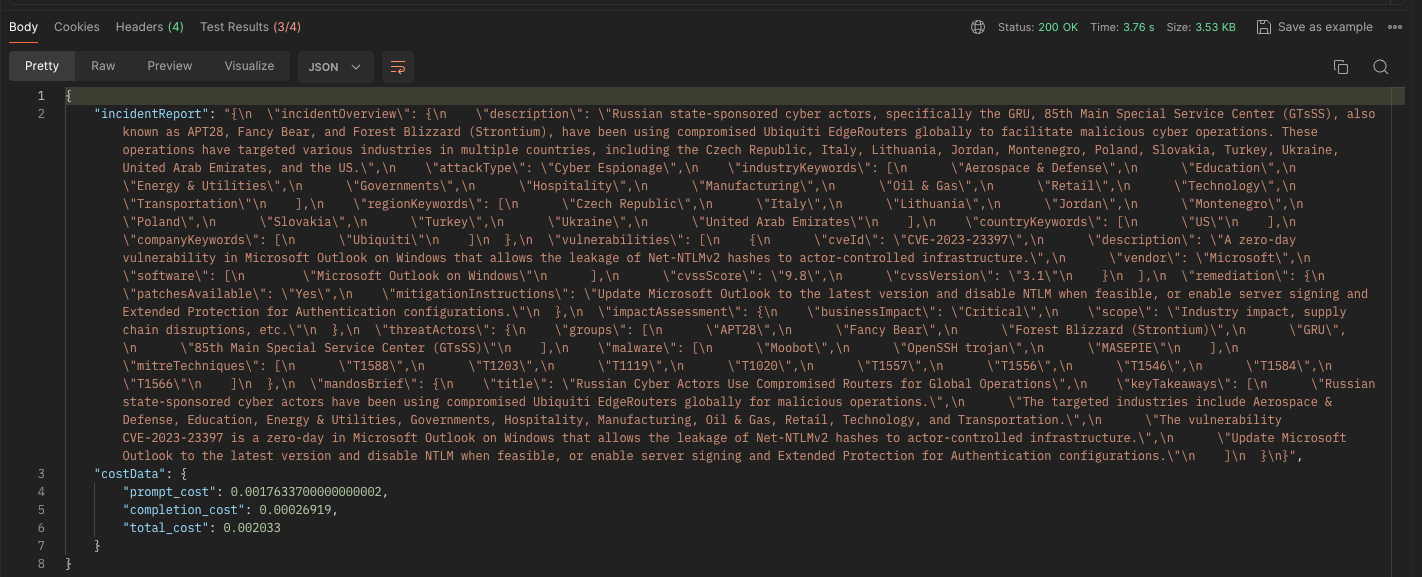
Model: mixtral-8x7b-32768
Speed (seconds): 3.76
Prompt Cost: $0.00176337
Completion Cost: $0.00026919
Total Cost: $0.002033
Content Awareness:
- Just like some of the previous models, Mixtral puts the list of affected countries in the JSON object for regions..
- Mixtral only adds 1 country to the list of countries out of 11.
- The only company extracted by the model is
Ubiquity. - Similar to GPT-3.5, this French model manages to insert the correct CVSS score and version. Also, I like the description of the vulnerability.
- This LLM does not full cover mitigation instructions.
"mitigationInstructions": "Update Microsoft Outlook to the latest version and disable NTLM when feasible, or enable server signing and Extended Protection for Authentication configurations."
},- Compared to other models the business impact provided by Mixtral is
Critical. - The model also detects multiple threat actors that are alternative names for the same actor
"APT28", "Fancy Bear", "Forest Blizzard (Strontium)", "GRU", "85th Main Special Service Center (GTsSS)" - Mixtral manages to capture two extra ATT&CK Techniques compared to LLAMA but still missed one.
- The model provides all 4 takeaways as requested.
"title": "Russian Cyber Actors Use Compromised Routers for Global Operations",
"keyTakeaways": [
"Russian state-sponsored cyber actors have been using compromised Ubiquiti EdgeRouters globally for malicious operations.",
"The targeted industries include Aerospace & Defense, Education, Energy & Utilities, Governments, Hospitality, Manufacturing, Oil & Gas, Retail, Technology, and Transportation.",
"The vulnerability CVE-2023-23397 is a zero-day in Microsoft Outlook on Windows that allows the leakage of Net-NTLMv2 hashes to actor-controlled infrastructure.",
"Update Microsoft Outlook to the latest version and disable NTLM when feasible, or enable server signing and Extended Protection for Authentication configurations."
]Comparative Analysis: Identifying the Best AI Language Models
Based on the evaluation results, let's highlight the best LLM for cyber threat intelligence for each category.
Fastest AI Language Model for Cyber Threat Intelligence
- Mixtral 8x7b LLM on Groq: 3.76 seconds
- LLAMA LLM on Groq: 4.46 seconds
- OpenAI's GPT-3.5: 11.83 seconds
- Anthropic's Claude 3 Sonnet: 26.83 seconds
- OpenAI's GPT-4: 28.15 seconds
- Anthropic's Claude 3 Opus: 52.30 seconds
Most Cost-Effective AI Language Model for Cyber Threat Intelligence
- Mixtral 8x7b LLM on Groq: $0.002033
- LLAMA LLM on Groq: $0.002574
- OpenAI's GPT-3.5: $0.003587
- Anthropic's Claude 3 Sonnet: $0.032331
- OpenAI's GPT-4: $0.07142
- Anthropic's Claude 3 Opus: $0.159105
AI Language Model with the Best Content Awareness for Cyber Threat Intelligence
- Anthropic's Claude 3 Opus: Accurately identified global scope, threat actor group, malware strains, and ATT&CK techniques. Missed some additional affected countries and companies.
- OpenAI's GPT-4: Solid understanding of key elements but missed some details like the complete list of ATT&CK techniques and certain mitigation instructions.
- Anthropic's Claude 3 Sonnet: Accurately identified key details like threat actors, malware strains, and ATT&CK techniques. Struggled with nuances and missed one mitigation recommendation.
- OpenAI's GPT-3.5: Impressive capabilities in extracting key information but struggled to provide complete mitigation instructions and identify all ATT&CK techniques.
- Mixtral 8x7b LLM on Groq: Mixed performance, accurately identified some critical information but missed several affected countries, companies, and mitigation instructions.
- LLAMA LLM on Groq: Struggled with accurately extracting and representing key details, output was incomplete and contained inaccuracies.
In summary, the Mixtral 8x7b LLM on Groq and LLAMA LLM on Groq excel in speed and cost, while Anthropic's Claude 3 Opus and Sonnet models demonstrate the best content awareness. OpenAI's GPT-4 and GPT-3.5 show solid performance in content awareness but lag behind in speed and cost compared to the Groq-based models.
Conclusion and Future Directions
In this evaluation, we compared the performance of large language models (LLMs) from Anthropic, OpenAI, Meta, and Mixtral in the context of cyber threat intelligence. By assessing each model's speed, content awareness, and total cost, we gained valuable insights into their suitability for specific cybersecurity use cases.
The results show that while all models demonstrate a degree of content awareness, there are notable differences in their ability to accurately identify and contextualize key information from the provided threat report.
Anthropic's Claude 3 Opus and OpenAI's GPT-4 exhibit strong content awareness, while OpenAI's GPT-3.5 and Mixtral's 8x7b models provide accurate CVSS scores and versions, despite this information not being explicitly mentioned in the report.
In terms of speed and cost, LLMs running on Groq's custom chips (LLAMA and Mixtral) process the content significantly faster and at lower costs compared to their counterparts, making them attractive options for organizations looking to optimize their cybersecurity workflows.
However, it is crucial to consider the limitations and caveats of this evaluation, such as the specific prompt, instructions, and content used, as well as the subjective nature of the assessment and potential differences in latency.
Moving forward, further research and development in prompt engineering, model fine-tuning, and specialized training data could potentially enhance the performance of these language models in cybersecurity threat intelligence tasks.
Additionally, exploring hybrid approaches that combine the strengths of different models or leverage ensemble techniques could yield even more robust and accurate threat analysis capabilities.
FAQ
What are AI language models, and how can they be used for cyber threat intelligence?
AI language models, such as GPT-4, GPT-3.5, and Claude, are advanced machine learning models that can understand and generate human-like text. These models can be used to analyze cyber threat reports, extract relevant information, and provide structured data for further analysis, helping organizations better understand and respond to cyber threats.
How do AI language models compare to traditional methods of cyber threat intelligence?
Traditional methods of cyber threat intelligence often involve manual analysis of threat reports by cybersecurity experts. AI language models can automate this process, quickly analyzing large volumes of data and providing structured insights. This can help organizations save time and resources while improving the speed and accuracy of threat detection and response.
What factors should be considered when choosing an AI language model for cyber threat intelligence?
When selecting an AI language model for cyber threat intelligence, consider factors such as:
- Speed: How quickly can the model analyze threat reports and provide insights?
- Content Awareness: How accurately can the model identify and extract relevant information from threat reports?
- Cost: What are the costs associated with using the model, including API usage and computational resources?
- Integration: How easily can the model be integrated into your existing cybersecurity workflows and tools?
Can AI language models replace human cybersecurity experts?
AI language models are powerful tools that can augment and support the work of human cybersecurity experts, but they cannot replace them entirely (at least not yet). Human expertise is still essential for interpreting the insights provided by AI models, making strategic decisions, and handling complex or novel threats.
How can organizations ensure the security and privacy of data when using AI language models for cyber threat intelligence?
When using AI language models for cyber threat intelligence, organizations should:
- Use secure API connections and authentication mechanisms to protect data in transit
- Ensure that the AI service providers have robust security and privacy practices in place
- Anonymize or pseudonymize sensitive data before feeding it into the AI models
- Regularly monitor and audit AI model usage to detect and prevent unauthorized access or misuse
What are the limitations of using AI language models for cyber threat intelligence?
Some limitations of using AI language models for cyber threat intelligence include:
- Dependence on the quality and relevance of the training data used to build the models
- Potential for biases or inaccuracies in the model's outputs, especially for complex or novel threats
- Limited ability to understand context or nuance in threat reports, which may require human interpretation
- Possible vulnerability to adversarial attacks or manipulation of input data to deceive the models
How can organizations get started with using AI language models for cyber threat intelligence?
To get started with using AI language models for cyber threat intelligence, organizations can:
- Identify the specific use cases and requirements for threat intelligence within their organization
- Evaluate and select appropriate AI language models based on factors such as speed, content awareness, cost, and integration
- Develop and test workflows for integrating AI language models into their existing cybersecurity processes and tools
- Train and educate cybersecurity teams on how to effectively use and interpret the insights provided by AI language models
- Continuously monitor and assess the performance of AI language models and iterate on their usage as needed
If this sparked your interest, I'd love to hear from you in the comments. Stay tuned for more and consider following me on LinkedIn and X.
Nikoloz